
Abstract
Extracting depth information from photon-limited, defocused images is challenging because depth from defocus (DfD) relies on accurate estimation of defocus blur, which is fundamentally sensitive to image noise. We present a novel approach to robustly measure object depths from photon-limited images along the defocused boundaries. It is based on a new image patch representation, Blurry-Edges, that explicitly stores and visualizes a rich set of low-level patch information, including boundaries, color, and smoothness. We develop a deep neural network architecture that predicts the Blurry-Edges representation from a pair of differently defocused images, from which depth can be analytically calculated using a novel DfD relation we derive. Our experiment shows that our method achieves the highest depth estimation accuracy on photon-limited images compared to a broad range of state-of-the-art DfD methods.
Video Presentation
Representaion
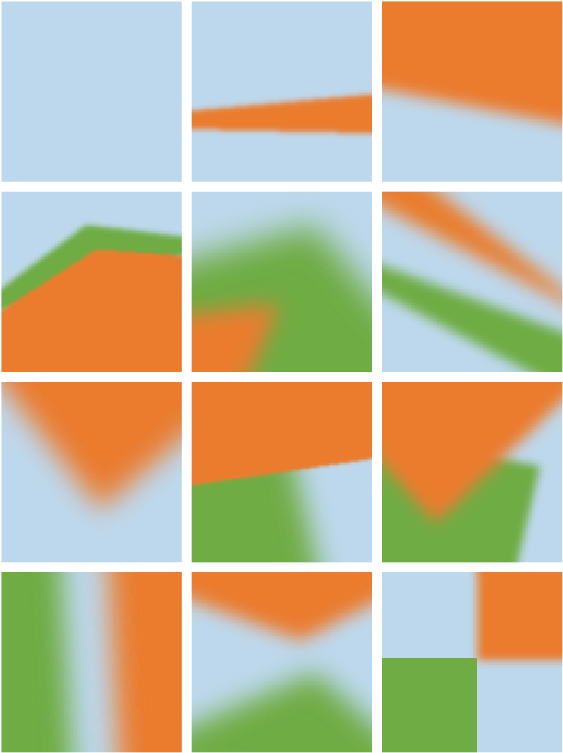
Blurry-Edges models each patch by a set of parameters, $\boldsymbol{\Psi} = \left( \{\boldsymbol{p}_i, \boldsymbol{\theta}_i, \boldsymbol{c}_i, \eta_i, i = 1,2,\cdots,l\}, \boldsymbol{c}_0\right)$. The tuple $(\boldsymbol{p}_i, \boldsymbol{\theta}_i, \boldsymbol{c}_i, \eta_i)$ parameterize the $i$th wedge in the patch, with $\boldsymbol{p}_i = (x_i, y_i)$ representing the vertex, $\boldsymbol{\theta}_i = (\theta_{i1}, \theta_{i2})$ denoting the starting and ending angle, $\boldsymbol{c}_i$ indicating the RGB color, and $\eta_i$ recording the smoothness of the boundary. The wedge with a large index is in the front. The vector $\boldsymbol{c}_0$ represents the RGB color of the background. As shown on the right, this representation can model various boundary structures and smoothness with only two wedges.
Model architecture
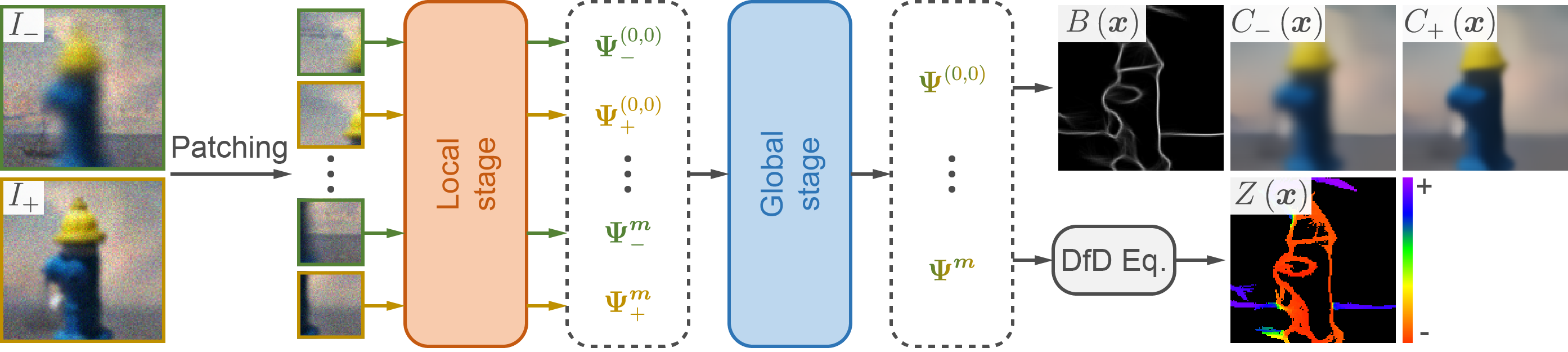
There are two stages. The local stage consists of residual blocks and predicts the Blurry-Edges representation for each patch locally. The global stage consists of a Transformer Encoder and refines the Blurry-Edges representation for all patches globally. Finally, the framework combines all the per-patch representations and outputs the global boundary map, color map, and depth map.
Comparison

Ground truth
Ours-W (2.962)

Focal Track (2.898)

PhaseCam3D (5.984)
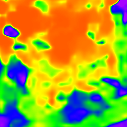
DFV-DFF (9.604)

Ours (1.922)

Ours-PP (1.748)
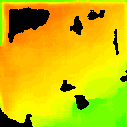
Tang et al. (2.838)

DefocusNet (5.480)
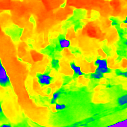
DEReD (6.611)

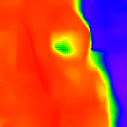


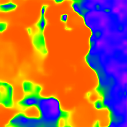

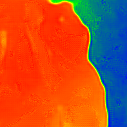




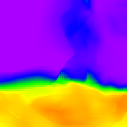

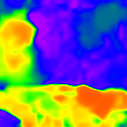


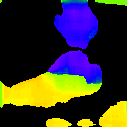






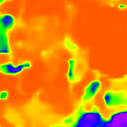






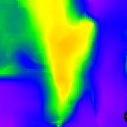
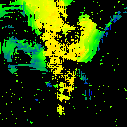
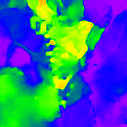
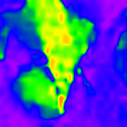


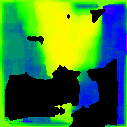

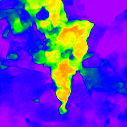





* The notations Ours, Ours-W, and Ours-PP refer to the sparse depth maps, dense depth maps from Blurry-Edges, and dense depth maps generated from the sparse depth maps using a U-Net as post-processing, respectively. Insert numbers are RMSE (cm) of the predict depth values.
Real-captured images

Input #1, shutter speed +

Input #2, shutter speed +

Reference

Depth map, shutter speed +

Input #1, shutter speed ++

Input #2, shutter speed ++

Depth map, shutter speed ++

Input #1, shutter speed +

Input #2, shutter speed +

Reference

Depth map, shutter speed +

Input #1, shutter speed ++
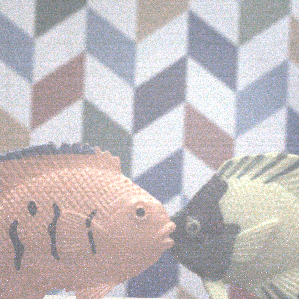
Input #2, shutter speed ++

Depth map, shutter speed ++

Input #1, shutter speed +

Input #2, shutter speed +

Reference

Depth map, shutter speed +

Input #1, shutter speed ++

Input #2, shutter speed ++

Depth map, shutter speed ++

Input #1, shutter speed +

Input #2, shutter speed +

Reference

Depth map, shutter speed +

Input #1, shutter speed ++

Input #2, shutter speed ++

Depth map, shutter speed ++
Poster
BibTeX
@inproceedings{xu2025blurry,
title={Blurry-Edges: Photon-Limited Depth Estimation from Defocused Boundaries},
author={Xu, Wei and Wagner, Charles James and Luo, Junjie and Guo, Qi},
booktitle={Proceedings of the Computer Vision and Pattern Recognition Conference},
pages={432--441},
year={2025}
}
118 cm
 75 cm
75 cm